[0508c29] …… 彼二童子聞此法已,踊在空中高七多羅樹,同聲讚佛:
……
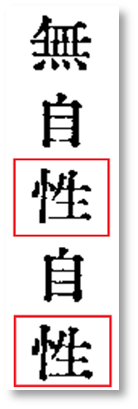
當求上菩提。 作生一切法,
作者不可得, 諸法從緣生,
無自性自性。』
「無自性自性」費解。看起來像是有一個字是「生」而抄錯了。「自性」和「自生」在空義論述中常并列,如《中論》:
自性即是自體,眾緣中無自性。自性無故不自生,自性無故他性亦無。
又如此經(《摩訶迦葉會》)的藏文版英譯:
此偈為:
All phenomena arise from causes,
But a creator cannot be apprehended.
Phenomena arise dependently,
But they do not really, by nature, emerge
1個讚
讀者您好,
本題「無自性自性」,檢原書圖檔同電子檔。對校房山石經(F08n0420_p0500a25)、《思溪藏》(日本增上寺藏宋版大藏經第14函第9冊第12圖第13行)、《高麗藏》(日本增上寺藏高麗版大藏經第20函第188冊第102圖第14行)均作「無自性自性」。
本題列入修訂參考。

關於「無自性自性」,剛好聯想到以下內容,沒有嚴謹地深究,故僅供參考。
玄奘法師所譯《大般若經》中每有「一切法皆以無性而為自性」(T07n0220_p0354a08)、「於一切法深生信解,皆以無性而為自性。」(T07n0220_p0363b04-05)等譯文。印順法師《初期大乘佛教之起源與開展》(Y37n0035_p0726a14-727a03)、《空之探究》(Y38n0036_p0141a05-142a03)對照奘譯與羅什譯本的不同,推論這可能與瑜伽學者對《般若經》的理解有關,但不確定是否所執梵本已有不同。
在不更動原經文字句的情形下,也許「以無性為聖道,以無性為現觀,達一切法皆以無性而為自性。由是因緣,當知一切法皆以無性為其自性。」(T07n0220_p0354a07-09)可以是一種理解方式。
感謝查證。
的確,硬要解是可以這麽解,但是那樣譯者可以直接寫成「無性為自性」。
這讓我想起另一件事。當我在寫這個post的時候,我原本是記得有幾部別的經文的校對注釋中有把「性」寫作「生」或反過來的,但是自己找不到了。現在有無什麽方便的辦法可以搜尋校對數據庫,例如列出所有A字和B字的對照關係?
1個讚
讀者您好,
謝謝回覆,
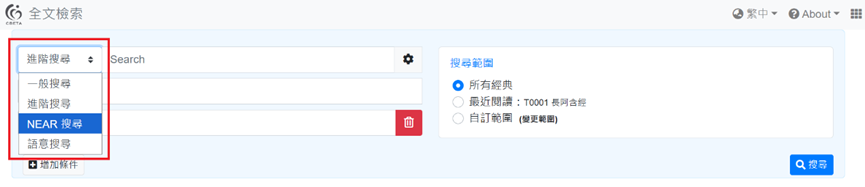
關於您提到希望可以快速搜尋注文中涉及「生」出注「性」者(反之亦然),個人是用「near 搜尋」(示範以本題為例)的方式處理的,供您參考。
步驟一:打開 CBETA Online 網頁,點選「進階搜尋」功能。
步驟二:左測第一格「進階搜尋」選單可下拉,請選擇「near 搜尋」。
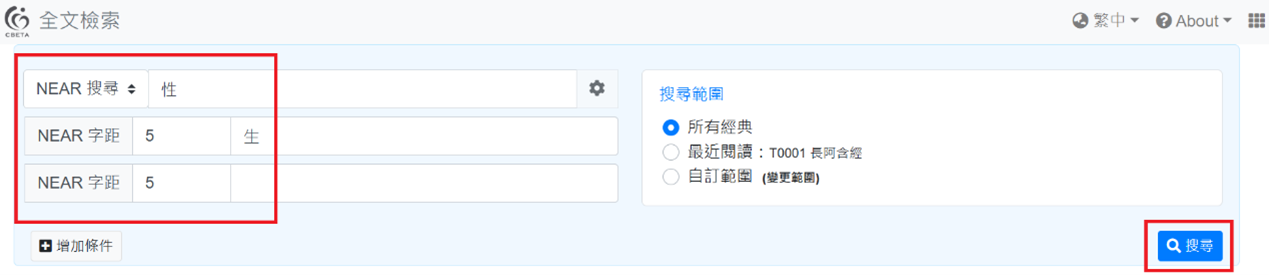
步驟三:左側紅框中的「5」代表字元間鄰近的距離,這也是可以調整的,不過因為此處「生」、「性」二字在注文中距離很近,所以我是依循此一預設模式。
接著於第一格輸入「性」,第二個輸入「生」(可依欲搜尋的目標文字自由代換),並按下右下角的藍色搜尋鍵。
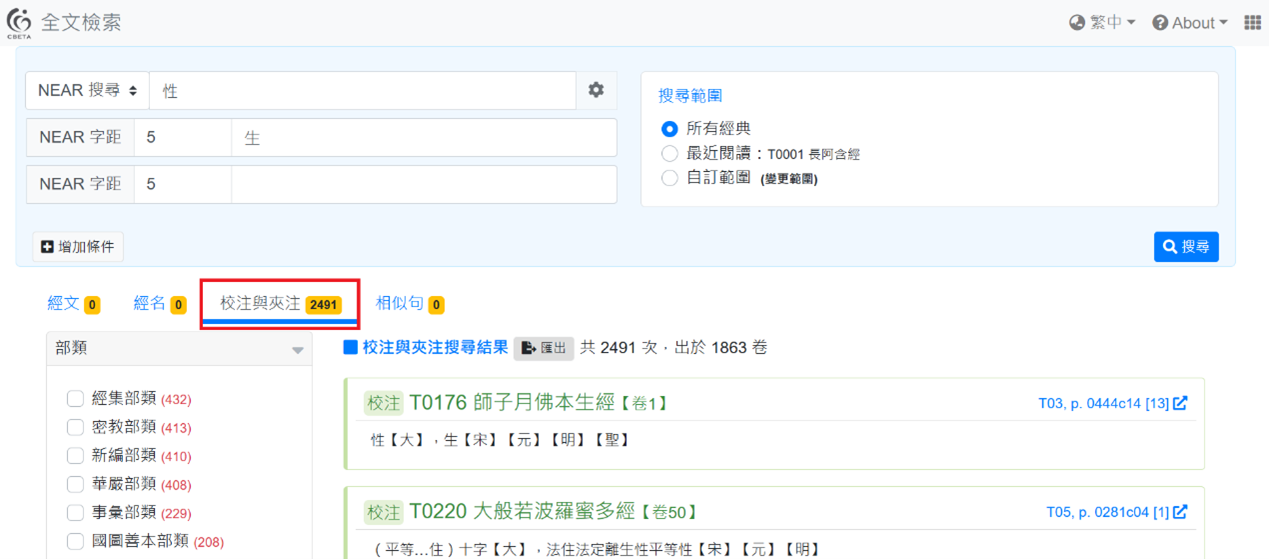
步驟四:點選下方的「校注與夾注」,就可以顯示校注與夾注中,字元距離在五個字以內的「生」、「性」(反之亦然)二字,此時就會有非常多案例出現了。
※ 以上是個人使用分享,或許有其他應用方式,這可以再請教 @Ray 師兄 

2個讚
真有創意!我都沒想到 NEAR 這方法!
我只想到搜 “性” AND “生”
這會搜到太多雜訊。
另外想到個進階的辦法,
下載含校注的純文字版 (https://cbdata.dila.edu.tw/stable/static_pages/download_text)
解壓縮後,用 VS Code 開啟整個資料夾,
然後用 Regular expression 搜: 生【.*性【|性【.*生【
我剛試找到 131筆.
或是用 grep 命令: grep -Er '生【.*性【|性【.*生【' .
得到結果如下:
./G/G2594/G2594_001.txt: [A30] 生【CB】,性【佛教】
./G/G2594/G2594_001.txt: [A31] 生【CB】,性【佛教】
./G/G2594/G2594_001.txt: [A32] 生【CB】,性【佛教】
./T/T1667/T1667_001.txt: [6] 性【大】,生【宋】【元】【明】
./T/T2016/T2016_062.txt: [1] 生【大】,性【元】【明】
./T/T2016/T2016_051.txt: [1] 生【大】,性【明】
./T/T1866/T1866_004.txt: [2] 生【大】,性【甲】【乙】【丙】
./T/T2089/T2089_001.txt: [20] 性【大】,生【戊】【己】
(後略)
另外看高手們有沒有秘技: @heavenchou , @Polar , @Ting , @jenjouhung
2個讚
@ray 我也有想過類似這個辦法,但是總是想著不夠方便就沒做。
其實用這個辦法的話,應該還可以統計出每個字在所有經文中的校訂紀錄,輸出所有可能的訛寫。
2個讚
如果您可以寫程式,又可以處理 XML 的話,
直接讀 XML,能找到比較精準的資料。
1個讚